Discord 机器人开发历程
前言
这篇文章最早写的是我第一次折腾 Discord 机器人时的记录。那时候的目标很简单:做一个能陪我聊天、查资料、发提醒、玩小游戏的机器人。
但这个项目后来一路变得很复杂。它经历过 Discord 双机器人、企业微信尝试、微信个人号方案调研、QQ 接入、NapCat 桥接、Web 后台、自我进化、Mem0 长期记忆、TTS、ASR、Tavily 联网搜索等一堆阶段。现在回头看,最重要的变化不是功能变多,而是边界终于清楚了。
现在的真实版本是:
- Discord 上只保留
shen-play,负责娱乐、轻互动、小游戏、抽卡和语音回复。 - QQ 上运行原本的
shen-test能力,现在叫刘新庚,负责 AI 对话、工具调用、提醒、Tavily 搜索、Mem0 记忆和自我进化。 - Web Admin 后台统一管理配置、模型、API Key、日志、QQ 桥接状态和自我进化数据。
- NapCat 负责 QQ 接入,后台通过 OneBot webhook 接收 QQ 私聊消息并回发。
所以这篇文章也按现在这个基本成型的版本重新整理一遍。
一、从 Discord 双机器人到 QQ + Discord 分工
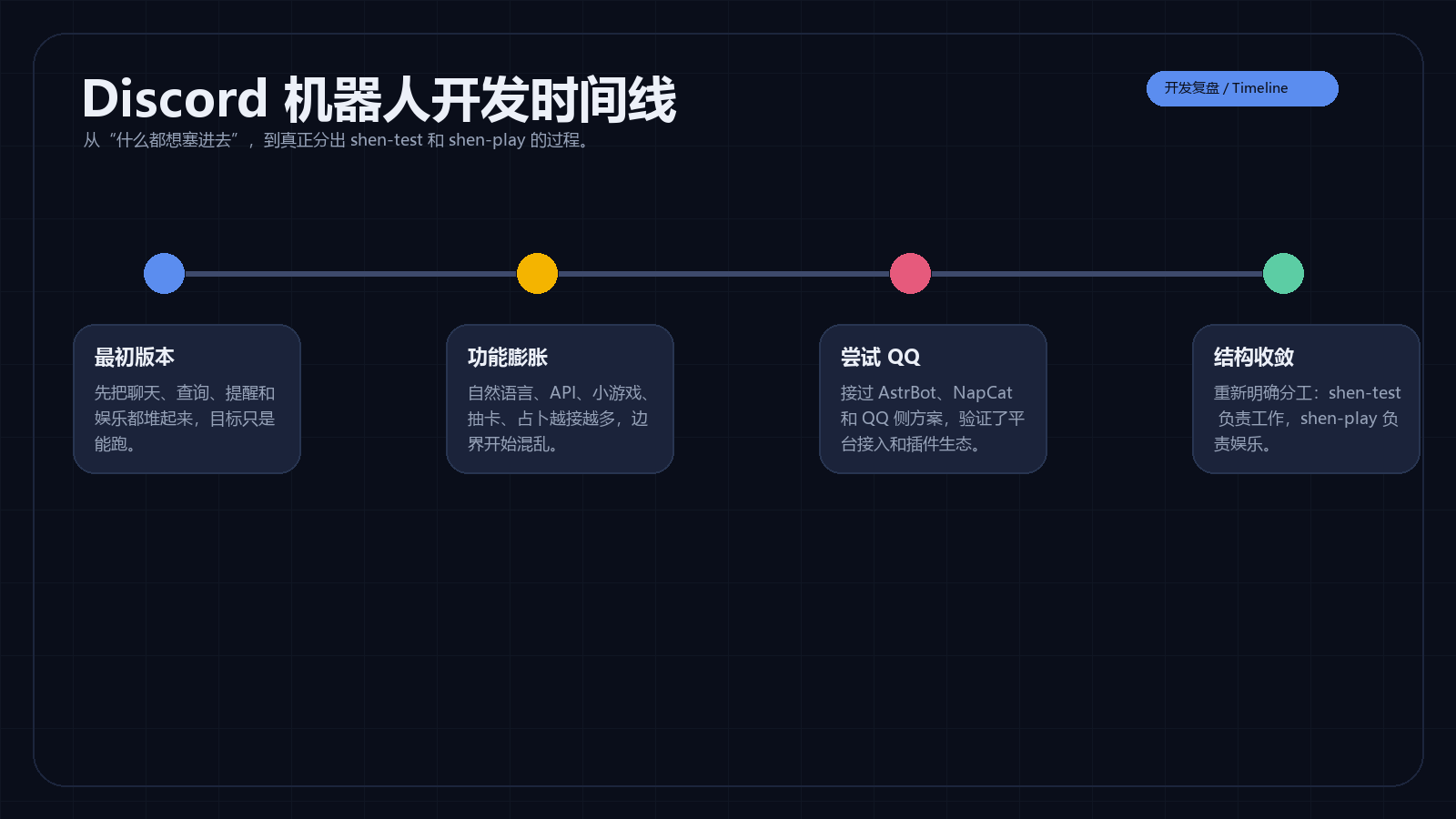
1. 最早的版本
最早我想做的是一套纯 Discord 机器人系统。
当时规划里有两个机器人:
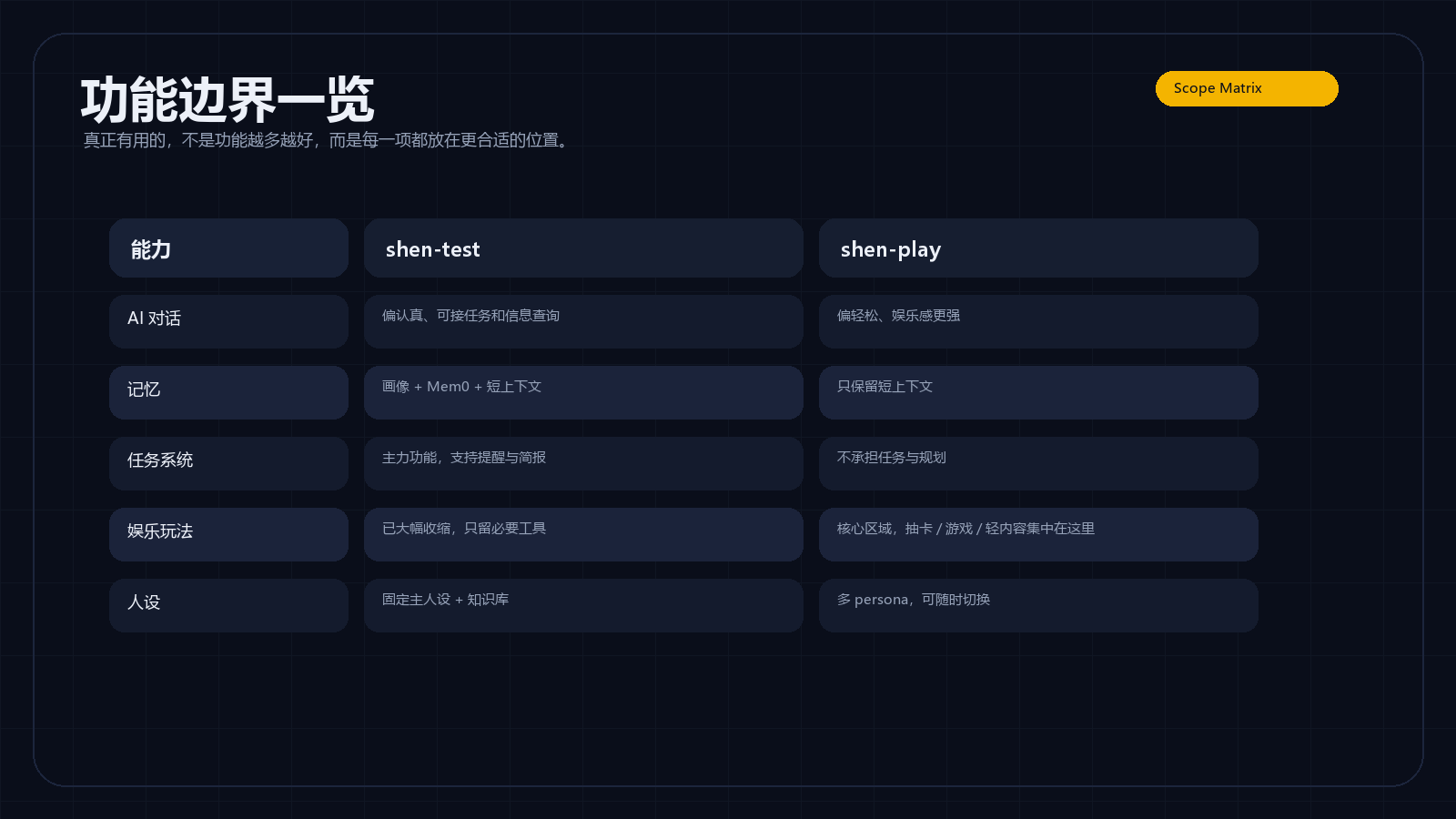
shen-test:偏工作、信息查询、任务提醒、生活管理。shen-play:偏娱乐、轻互动、小游戏和抽卡。
这个思路本身是对的,因为工作助理和娱乐机器人确实不应该混成一个人格。工作助理需要稳定、准确、可追踪;娱乐机器人需要轻松、快、有一点玩具感。
但问题也很现实:我平时不一定开着梯子,而 Discord 在国内使用体验不稳定。如果真正想把 AI 助理当成日常入口,只放在 Discord 里并不顺手。
2. 中间试过的方案
为了让机器人能在国内更方便地使用,我中间试过不少方案。
企业微信
企业微信的优点是官方、稳定、容易部署,适合做通知和企业内部工具。但它的体验更像“工作机器人”,不像一个自然聊天的个人 AI 朋友。它可以用,但不是我最想要的那种入口。
微信个人号方案
我也查过 OpenClaw 这类方案。理论上可以把 AI 接到微信个人号里,但限制比较多,比如 iOS 端、主动推送、账号绑定、服务资源等问题。最后我没有继续走这条线。
QQ + NapCat
最后真正落地的是 QQ。
QQ 的好处是:
- 我不用开梯子就能聊。
- NapCat 可以通过 OneBot 协议接入。
- 私聊体验比企业微信更接近日常聊天。
- 主动提醒、TTS、文件、图片等能力也更容易扩展。
所以现在的结构变成了:
- QQ:承接原
shen-test的严肃助理能力。 - Discord:只保留
shen-play,继续做娱乐和轻互动。

二、当前架构
现在项目已经不是单纯的 Discord bot,而是一套小型机器人系统。
1. QQ 机器人:刘新庚
QQ 机器人是现在的主助理,也就是原来 shen-test 的继承者。
它现在负责:
- 日常 AI 对话
- Tavily 联网搜索
- 模型切换
- 图片理解
- 文生图
- ASR 语音转文字
- TTS 语音回复
- 定时提醒
- 定时任务
- 文件直发
- Mem0 长期记忆
- 本地画像
- 自我进化
- 主动问候逻辑
它只监听我的 QQ 私聊,不监听群聊,也不回复其他人的消息。这个限制是刻意做的,因为这套机器人目前主要是个人助理,不是公开客服或群机器人。
2. Discord 机器人:shen-play
Discord 上现在只保留 shen-play。
它负责:
- 娱乐聊天
- 人设切换
- 小游戏
- 抽卡
- 卡片生成
- 俳句
- 运势
- 星座
- TTS 开关
- 轻量模型切换
shen-play 不再承担长期记忆和任务助理职责。它更像一个放松用的娱乐机器人,而不是一个严肃助理。
3. Web Admin 后台
后台是这次项目成熟以后最重要的一部分。
它现在负责:
- 查看服务状态
- 查看 QQ 桥接状态
- 查看 NapCat 状态
- 管理模型配置
- 管理 API Key
- 管理 TTS 配置
- 管理视觉模型和生图模型
- 查看 QQ 日志
- 查看 shen-play 日志
- 编辑人设和知识库
- 查看自我进化日志
- 查看 Mem0 记忆摘要
- 查看和编辑本地用户画像
后台地址绑定到了单独域名,直接通过浏览器访问即可。
三、QQ 机器人现在怎么工作
1. NapCat 接入
QQ 消息由 NapCat 接收,然后通过 OneBot webhook 发给 Web Admin。
大概流程是:
- 我在 QQ 私聊机器人。
- NapCat 收到消息。
- NapCat 把 OneBot 事件 POST 到后台。
- 后台判断是否是我的私聊。
- 后台加载
qq-botruntime 处理消息。 - 生成文本、图片、语音或文件。
- 后台再通过 NapCat API 发回 QQ。
这样做以后,QQ 机器人不需要像 Discord bot 那样自己保持网关连接,后台就是整个 QQ 桥接的中枢。
2. 只监听我一个人
目前 QQ 机器人只处理 QQ_OWNER_ID 对应的私聊消息。
也就是说:
- 不是我的 QQ,不回复。
- 群聊,不回复。
- 其他事件,不处理。
这个限制让系统更安全,也避免误触发。等以后真想加多人,再单独做授权列表,而不是一开始就开放。
3. 自然语言比命令更重要
QQ 入口最重要的是自然语言。
我不想每次都输入复杂命令,所以现在它会识别很多自然说法,例如:
- “提醒我明天下午三点做某事”
- “每天早上九点给我发简报”
- “给阿嬷的情书评分多少,你看看”
- “导演是谁,你查查”
- “帮我生成一张图片”
- “开启语音回复”
当然,自然语言也很容易误判,所以这块后来做了不少收紧:
- 明确提醒才创建提醒。
- 涉及实时信息时必须走 Tavily。
- 不允许模型假装自己查过。
- 文件、图片、语音输出统一交给后台发送。
四、Tavily 联网搜索
联网搜索是这次项目里很重要的一块。
之前有一个坑:模型有时会在没有真实联网的情况下说“刚给你查到了”。这很危险,因为它看起来像查了,其实是在编。
现在我做了更明确的规则:
- 只要我说“上网查”“联网查”“查查看”“你看看”“搜一下”等,就强制走 Tavily。
- 只要涉及“最新”“今天”“今年”“评分”“票房”“上映”“新闻”等实时信息,也优先走 Tavily。
- Tavily 搜到结果以后,再交给模型总结。
- 如果结果不足,必须说不确定,不能编造。
举个例子,我问:
给阿嬷的情书评分多少,你看看
现在流程不是直接让模型回答,而是:
- 提取搜索词。
- 调用 Tavily。
- 得到豆瓣、新闻、票房等搜索结果。
- 再让模型基于搜索结果回答。
这个改动让机器人从“看起来聪明”更接近“真的可靠”。
五、记忆和自我进化
这是我最在意的部分。
我希望它不是一个每次都从零开始的聊天机器人,而是一个会越来越懂我的长期助理。
现在它的记忆分成三层。
1. 短期上下文
短期上下文负责当前这段聊天的连贯性。
比如我刚问了一部电影,下一句问“导演是谁”,它能知道我还在说同一部电影。
2. Mem0 长期记忆
Mem0 负责外部长期记忆。
它会保存一些对话中有长期价值的信息,后续聊天时再检索回来。后台也能查看 Mem0 的记忆摘要,并把英文记忆转成更适合我看的中文摘要。
3. 本地结构化画像
本地画像是更稳定的一层。
它记录的不是所有聊天内容,而是更长期的东西,比如:
- 我的身份和长期项目
- 我的回答风格偏好
- 我的工作流习惯
- 我不喜欢什么
- 我常用的提醒方式
- 我最近的互动状态
这层画像会参与后续回复,让机器人慢慢贴合我的说话方式和使用习惯。
4. 自我进化现在真实怎么跑
现在自我进化已经不是只写在代码里的概念,而是在后台真实跑起来了。
当前逻辑是:
- QQ 后台启动时,会启动一个
qq-evolution后台线程。 - 每 10 分钟检查一次。
- 每 30 分钟从 Mem0 扫描一次可用长期记忆。
- 只针对 QQ owner 运行,不再扫 Discord 用户。
- 高价值、稳定、非敏感的信息会自动合并进本地画像。
- 一次性搜索事实不会合并进画像。
这里踩过一个坑:一开始它会把电影评分、导演、票房这种临时搜索事实也写进画像,这明显不对。后来我加了过滤,只保留真正能代表“我是谁、我偏好什么、我长期在做什么”的内容。
现在更合理的判断是:
- “用户喜欢某种回答风格”可以进画像。
- “用户长期在做某个研究项目”可以进画像。
- “用户要求实时信息必须联网确认”可以进画像。
- “某部电影豆瓣 9.1 分”不应该进画像。
这一层过滤很关键,因为自我进化不是记得越多越好,而是要记得对。
六、TTS、ASR 和多模态能力
1. ASR
QQ 机器人支持语音转文字。
如果我直接发语音,它会先走 ASR,把语音转成文本,再按普通文本消息继续处理。这样我在手机上不用打字,也能直接和它说话。
2. TTS
TTS 现在统一由后台配置和机器人命令配合控制。
目前主要支持:
- Edge TTS
- SiliconFlow TTS
TTS 是否开启,主要在对话里决定,不再只靠后台开关。这样更符合实际使用:有些场景我想听语音,有些场景只想看文字。
3. 图片理解和生图
图片理解和生图现在也做成了可配置项。
后台可以指定:
- 视觉理解提供商
- 视觉理解模型
- 生图提供商
- 生图模型
这样后面换模型不需要改代码,直接在后台配置即可。
七、提醒和主动消息
QQ 相比 Discord 最大的优势之一,就是更适合作为日常入口。
现在 QQ 机器人支持:
- 一次性提醒
- 每日任务
- 定时主动发送
- 晨间简报
- 主动问候逻辑
提醒和任务由后台 scheduler 负责扫描,到时间后通过 NapCat 主动发 QQ 私聊。
这点很重要,因为原来 Discord 上就算机器人发了,我不开梯子也收不到。现在迁到 QQ 后,这个问题基本解决了。
八、Web Admin 后台
后台现在是整个项目的控制台。
它不是一个装饰页面,而是实际运维入口。
1. 首页状态
首页能看到:
- QQ 桥接状态
- NapCat 状态
- shen-play 状态
- 后台服务状态
- 最近日志
2. 配置管理
配置分成几类:
- 机器人 token
- 模型配置
- API Key
- TTS 配置
- 图像与视觉模型配置
其中模型部分已经按 provider 拆分,方便后面增删模型。
3. 日志
后台有 QQ 机器人日志和 shen-play 日志。
日志区域固定高度,内部滚动,不会把页面撑得很长。
4. 自我进化页
自我进化页现在能看到:
- 用户画像
- 自我进化日志
- Mem0 记忆摘要
- 运行数据
- 主动问候设置
这页目前已经比最早直观很多,但后面还可以继续优化,比如把“最近学到了什么”“哪些被过滤掉”“下次扫描时间”做得更清楚。
九、shen-play 的定位
Discord 上现在只保留 shen-play。
它的定位很明确:娱乐和轻互动。
保留的方向包括:
- 人设
- 轻聊天
- 抽卡
- 小游戏
- 俳句
- 运势
- 星座
- TTS
- 模型切换
shen-play 不再和 QQ 助理抢功能。它不负责长期画像,也不负责我的日常提醒。这样反而更轻、更纯粹。
对我来说,这个拆分很重要:
- QQ 里的刘新庚是日常助理。
- Discord 里的 shen-play 是娱乐搭子。
一个负责把事情做稳,一个负责玩得开心。
十、部署和稳定性
这个项目现在已经不靠手动运行脚本了,而是服务器上的 systemd 服务。
当前主要服务是:
discord-bot-admin.serviceshen-play-bot.service
QQ 的核心逻辑跑在 discord-bot-admin 里,因为 QQ 消息是由后台通过 NapCat webhook 处理的。
部署脚本现在会:
- 上传代码。
- 远端编译检查。
- 保留线上运行时数据。
- 重启后台和 shen-play。
- 查看服务状态和日志。
这里也踩过一个坑:早期部署脚本会把本地 qq-bot/data 上传到服务器,差点覆盖线上画像、记忆、日志。后来我把运行时数据全部排除掉,只同步代码和静态资源。
这件事让我意识到,机器人项目后期最重要的不是“再加一个功能”,而是:
- 不要丢数据
- 不要误覆盖配置
- 不要让后台线程悄悄死掉
- 日志一定要能查到
十一、现在的真实状态
现在这套系统已经基本成型。
真实状态是:
- Discord 上只有
shen-play。 - QQ 上运行刘新庚,也就是原
shen-test的能力迁移版。 - QQ 只监听我的私聊。
- NapCat 已经接入并能收发消息。
- Tavily 能正常联网搜索。
- Mem0 已接通。
- 自我进化后台线程已启动。
- QQ 画像会自动更新。
- 后台能查看日志和配置。
- 服务部署在服务器上,systemd 常驻运行。
它还不是最终形态,但已经从“能跑”走到了“能长期用”。
以后我可能继续做的方向:
- 更清晰的自我进化可视化
- 更稳定的语音情绪 TTS
- 更细的记忆纠错机制
- 更好的任务复盘
- QQ 文件和图片能力继续增强
- shen-play 的娱乐体验继续打磨
十二、总结
这个项目最有意思的地方,是它不是一次性写完的。
它从一个 Discord 聊天机器人,慢慢变成了一套跨平台的小型 AI 助理系统。中间做过很多尝试,也删掉过很多东西。最后留下来的不是最花哨的版本,而是最符合我真实使用习惯的版本:
- 工作和生活入口放到 QQ。
- 娱乐和陪玩留在 Discord。
- 配置、日志、模型、记忆、自我进化交给后台。
- 长期记忆和本地画像一起工作。
- 工具调用尽量真实,不让模型假装查过。
对我来说,这才是这个项目真正成型的地方。
不是做了一个机器人,而是慢慢做出了一个能进入日常生活的 AI 入口。
项目和后台地址
项目仓库:
https://github.com/yys806/discord-bot
Web Admin 后台: